浏览器运行Deepseek本地模型
DeepSeek 浏览器浏览器运行DeepSeek本地模型
0.前言
DeepSeek很火,毋庸置疑的火。一火吧,用的人就多,官网那个就卡,不然也不会有那么多第三方部署。也有很多本地部署的方案,比如基于Ollama部署。
但如果只是想尝尝鲜、玩一玩,不想折腾那么复杂的运行环境,那可以看看本文,直接在浏览器里运行DeepSeek。
1.浏览器中运行DeepSeek
为了在浏览器中高效运行DeepSeek,Hugging Face提供了transformers.js库,该库利用WebGPU技术来加速模型的推理过程。
同时,Hugging Face也提供了一系列适用于transformers.js的ONNX格式模型权重文件。
有运行时也有模型,开搞!
有NodeJS环境
推荐使用Node18,减少踩坑。
clone代码、run一把梭。
git clone https://github.com/huggingface/transformers.js-examples.git
cd transformers.js-examples/deepseek-r1-webgpu
npm i
npm run dev
在浏览器中输入http://localhost:5173打开页面,按操作提示加载模型后,即可和DeepSeek模型对话。
没有NodeJS环境
一点小小的限制:因为运行大模型是一个计算密集型的任务,为了不阻塞主线程,所以需要在worker线程中运行DeepSeek推理。
这就带来个新的问题,如果在本地双击html文件打开时,Web Worker会因为跨域限制而无法加载脚本。浏览器要求Web Worker的脚本必须通过 HTTP/HTTPS 协议加载,而不是直接从本地文件系统加载。
所以仍然需要一个HTTP服务器来提供文件服务。下载文件(https://github.com/Mrliduanyang/zhouzhou/blob/main/杂七杂八/dist.tar.gz),解压,然后在index.html所在路径下执行
# Mac和Linux系统都有基本的Python环境,Windows系统可自行下载安装Python环境
python3 -m http.server 5173
启动HTTP服务器。
在浏览器中输入http://localhost:5173打开页面,按操作提示加载模型后,即可和DeepSeek模型对话。
测试
在一台2019年,2.6 GHz 六核Intel Core i7的MacBook Pro上,速度可以达到7token/s。
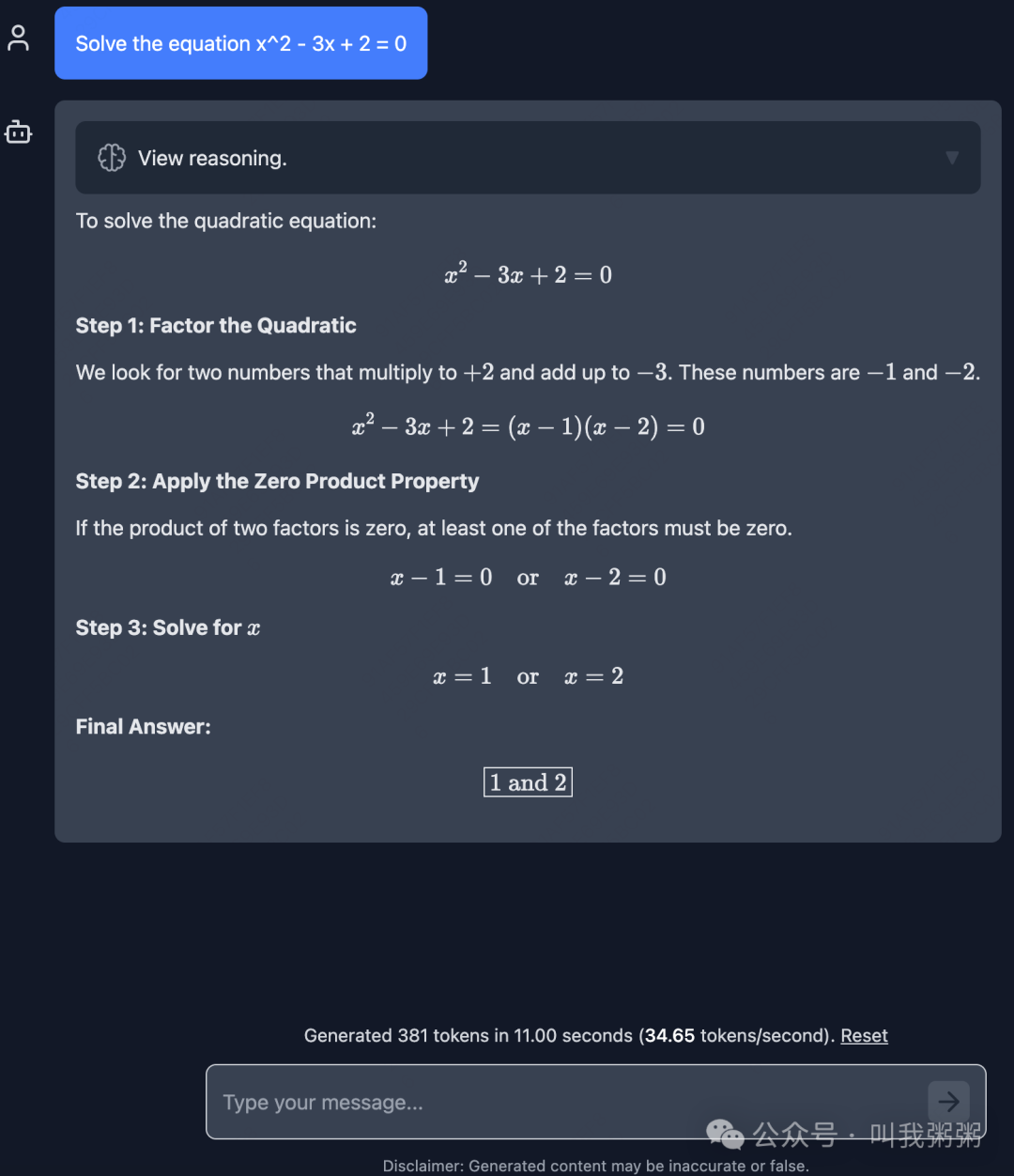
在一台2021年,Apple M1 Pro的MacBook Pro上,速度可以达到34token/s。
简单问了一个数学题,效果如下:
参考资料
https://github.com/huggingface/transformers.js-examples/tree/main/deepseek-r1-webgpu